
Elasticsearch in der Praxis: Schnelle Suche in Dokumenten
Zuerst erschienen in der public Ausgabe 01-2022
von Laszo Lück
Auch im behördlichen Umfeld wachsen Anzahl und Umfang unstrukturierter Datensätze in nahezu exponentiellem Ausmaß. Die Frage ist heute weniger, ob eine bestimmte Information vorliegt, sondern ob sie – in absehbarer Zeit – gefunden werden kann. Dokumentenbestände sollen in zahlreichen vernetzten Verfahren, wie zum Beispiel als Anforderung an Registermodernisierungen, schnell und komfortabel über Systemgrenzen hinweg durchsuchbar sein. Dieser Artikel stellt die dokumentenbasierte Such-Technologie Elasticsearch vor und erklärt, mit welchen architektonischen Mitteln diese arbeitet. Es werden Unterschiede zu relationalen Datenbanken erklärt sowie Vor- und Nachteile abgewogen, die sich bei der Planung des Systems und möglicher Datenmodelle ergeben können.
Historie
Dokumentenbasierte Suchmaschinen sind im Vergleich zu relationalen Datenbanken eine deutlich neuere Technologie. Elasticsearch1 wurde 2010 entwickelt, im Vergleich dazu ist Oracle2 seit 1979 auf dem Markt. In den vergangenen zehn Jahren haben sich dokumentenbasierte Suchmaschinen aber als feste Größe etabliert. Relationale Datenbanken wurden in den 1970er-Jahren entwickelt, als Speicher deutlich kostspieliger war als die Arbeitszeit für Anwendungsentwicklung. Um Speicherplatzverbrauch zu minimieren, wurden Relationen zwischen strukturierten Datensätzen erdacht, die eindeutige Verbindungen zwischen diesen Datensätzen ermöglichen. Der Vorteil relationaler Datenbanken ist ein hoher Grad der Datenkonsistenz, der unter anderem durch das Speichern auf nur einem System und die verwendete Relation der Daten zueinander erreicht wird. Gleichzeitig ist dadurch eine Verteilung der Daten auf mehrere (verteilte) Rechnersysteme jedoch nicht möglich.
NoSQL-Datenbanken („non-SQL“ oder „not only SQL“), wie beispielsweise MongoDB oder Elasticsearch wurden in den späten 2000er-Jahren mit dem Schwerpunkt auf Skalierung, mit schnellen Abfragen, häufigen Anwendungsänderungen und einfacherer Programmierung entwickelt. Dabei wird bewusst in Kauf genommen, dass im Gegensatz zu relationalen Datenbanken durch Redundanz mehr Speicherplatz benötigt wird. Die Preise für Speicher sind in den letzten Jahrzehnten erheblich gesunken, während die Kosten für Softwareentwicklung stark gestiegen sind.
Lucene-Index
Lucene wurde 1997 von Doug Cutting als Volltext-Suchbibliothek entwickelt. Seit 2001 ist Lucene Teil des Jakarta-Projektes und seit 2005 Hauptprojekt der Apache Software Foundation.3
Abbildung 1: Bestandteile einer Elasticsearch-Instanz
Aufbau von Elasticsearch
Lucene
Elasticsearch ist eine in Java geschriebene Suchmaschine, die im Kern auf Apache Lucene4 aufbaut. Lucene stellt die Funktionalität der Volltext-Suche und -Indexierung bereit, die durch Elasticsearch um verschiedene Komponenten erweitert werden, die eine Hochverfügbarkeit, die Skalierbarkeit und vereinfachte Sucheingaben ermöglichen.
Speicherung auf Basis von Dokumenten
Kernelement von Elasticsearch und Abgrenzung zu relationalen Datenbanken ist die Speicherung von Informationen auf Basis von Dokumenten. Ein Dokument ist eine Zusammenfassung von Daten, die fachliche Informationen beinhalten. Als Beispiel sei hier ein Dokument „Person“ genannt. Dieses Dokument enthält Attribute wie „Vorname“, „Nachname“, „Geburtsdatum“ usw.
Indices
Ein Index ist die größtmögliche Dateneinheit in Elasticsearch. Indices sind logische Partitionen, in denen Dokumente gleichen Typs gespeichert werden. Ein Index ist in seinem Aufbau vergleichbar mit einer Datenbank im RDBMS-Umfeld. In Elasticsearch können beliebig viele Indices definiert werden. Indices können in mehrere Sub-Indices aufgeteilt werden, um eine höhere Suchperformance durch das Verteilen der Daten auf mehrere physikalische Server-Knoten zu erreichen (siehe Abbildung 2). Von außen betrachtet verhält sich ein Verbund aus mehreren Sub-Indices wie ein einzelner Index. Suchanfragen werden durch Elasticsearch optimiert, sodass nur die Knoten angefragt werden, die auch potenziell ein Suchergebnis enthalten.
Abbildung 2: Aufteilung in Sub-Indices und Verteilung auf mehrere Server-Knoten
Sharding
Ein weiteres Kernkonzept, das Elasticsearch performant, skalierbar und flexibel macht, ist die Fragmentierung (englisch: Sharding). Bei dieser Methode der Datenbankpartitionierung wird der Datenbestand in mehrere Teile, die sogenannten Shards („Splitter“ oder „Scherbe“), geteilt und auf jeweils eigenen Server-Knoten verwaltet. Als Beispiel dient eine Menge Dokumente mit einer Gesamtgröße von einem Terabyte. Das Hardware-Cluster, das als Elastic-Such-Cluster verwendet werden soll, besteht aus zwei Knoten mit jeweils 500 Gigabyte Speicherkapazität (ohne Berücksichtigung von Redundanzen und Bedarf an Speicherplatz für die interne Datenverwaltung).
Wenn die Größe eines Index die Kapazitäten eines einzelnen Knotens wie in diesem Szenario überschreitet, kommt bei Elasticsearch das sogenannte Sharding ins Spiel. Wird ein Index in Shards unterteilt, werden die Dokumente aus diesem Index in jeweils nur einem der zugehörigen Shards gespeichert. Technisch gesprochen wird ein Elasticsearch-Shard als einzelne Instanz eines Lucene-Index realisiert. Shards kann man sich wie eine selbstständige Suchmaschine vorstellen, die Abfragen nach einem Teilsatz von Daten in einem Elasticsearch-Cluster indexiert und verarbeitet. Shards bieten den Vorteil, dass sie auf jedem Knoten eines Serververbundes (Cluster) betrieben werden können. Ein Knoten kann dabei unterschiedlich viele Shards betreiben. Die in ein Shard geschriebenen Daten werden in regelmäßigen Abständen in neue, nicht mehr veränderbare Lucene-Segmente auf einem Datenträger veröffentlicht und damit für Abfragen verfügbar gemacht.
Replikation
Replicas dienen der Ausfallsicherheit in Elasticsearch und sind im Grunde Kopien der Shards eines Index. Der originale Shard wird dabei als Primary Shard bezeichnet. Ist ein Knoten nicht verfügbar, kann die Anfrage von einem anderen Knoten beantwortet werden, der die Daten ebenfalls vorhält. Replikation ist fester Bestandteil einer Elasticsearch-Implementierung und trägt so zur Datensicherheit und Performance bei.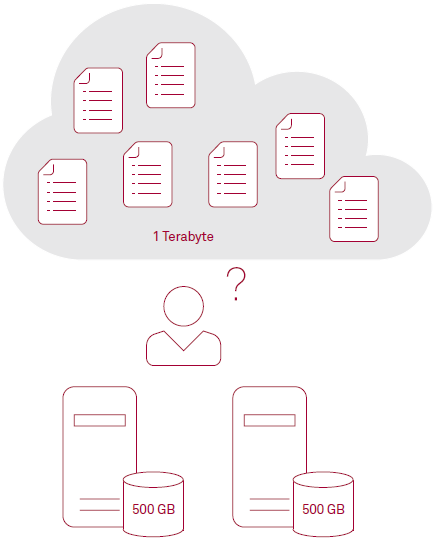
Abbildung 3: Die Datenmenge ist größer als der auf einem Knoten zur Verfügung stehenden Speicherplatz

Abbildung 4: Aufteilung eines Index in Shards
Zudem können Replicas die Suchleistung erhöhen, wenn die Rechenleistung mehrerer Knoten parallel für die Suche verwendet wird.
Bei NoSQL-Systemen werden Sharding und Replikation oft verknüpft. Dabei wird zum Beispiel in einer ringförmigen Server- Anordnung jedes Shard auch gleichzeitig auf einen oder mehrere nachfolgende Server im Ring repliziert. Somit hält jeder Server eine Kopie mehrerer Shards. Durch diese Anordnung und die dazugehörigen Mechanismen zum Datenabgleich entstehen flexible und fehlertolerante Systeme, die auch mit sehr großen Datenmengen befüllt werden können.
Die Anzahl an Shards und Replicas kann bei der Erstellung eines Index frei definiert werden. Während die Zahl der Shards eines Index konstant bleiben muss, kann die Zahl der Replicas jederzeit angepasst werden. Zu viele Replicas führen jedoch zu mehr Overhead und Ressourcenverbrauch und können die Leistung und Geschwindigkeit des gesamten Clusters negativ beeinflussen. Werden zu viele Shards gebildet, wirkt sich das ebenfalls negativ aus – sowohl auf die Performance einzelner Knoten als auch auf das Gesamtsystem, weil jeder Shard eine entsprechende Menge Hauptspeicher und CPU-Ressourcen verwendet. Man spricht hier von Oversharding5. In Elasticsearch benutzt ein Shard exakt einen CPU-Thread. Werden zu viele Shards gebildet (erheblich mehr als CPU-Cores pro Knoten), wirkt sich dies ebenfalls negativ auf die Suchgeschwindigkeit aus. Daher ist eminent wichtig, vor der Planung eines Elasticsearch- Systems eine sogenannte Sharding- Strategie zu entwickeln, um spätere Probleme beim Betrieb eines solchen Systems zu vermeiden.6
Abbildung 5: Verteilung von Shards und Replicas auf mehreren Knoten
Vor- und Nachteile
Der sehr hohen Geschwindigkeit der Suche mit Elasticsearch stehen eine relativ geringe Schreib- und Indexierungsgeschwindigkeit und damit verbunden eine hohe Rechenlast gegenüber. Das hängt damit zusammen, dass beim Schreiben jedes Dokumentes in Elasticsearch das Dokument selbst und die enthaltenen Attribute analysiert und je nach Datentyp und -menge in unterschiedliche Metastrukturen geschrieben werden. Das kann dann zum Problem werden, wenn in kurzer Zeit viele Dokumente geschrieben werden und damit die Indexierungsdichte sehr hoch ist.
Mithilfe von Sharding und Replikation kann die Indexierung von Dokumenten und die Suche der Inhalte voneinander getrennt werden. Dafür sind für die Indexierung der Daten Server-Knoten mit hoher Rechenleistung und Verarbeitungsgeschwindigkeit notwendig. Für die eigentliche Suche werden hingegen andere Knoten mit hoher Lesegeschwindigkeit und viel (Haupt-)Speicher eingesetzt. Mit den Möglichkeiten der Indexierung, des Shardings und der Replikations-Mechanismen ist eine sehr hohe Skalierung möglich, die die relativ langsame Indexierungsverarbeitung der Daten wettmachen kann. Die Skalierung mit beliebigen Server- Ressourcen über Rechenzentrumsgrenzen hinweg ermöglicht eine sehr viel höhere Suchperformance als bei einem relationalen Datenbankmanagementsystem auf nur einem Server. Elasticsearch ist – wie auch die meisten anderen Vertreter des NoSQL-Ansatzes – als quelloffenes Produkt kostenlos einsetzbar, unterliegt jedoch Lizenzbedingungen. 7
Bei der Planung eines solchen Systems muss der erhöhte Speicherbedarf bedacht werden, der durch die dokumentenbasierte Speicherung, die dadurch bedingte Aufteilung der Daten und redundante Datenablage sowie die Replikation über die Server-Knoten entsteht. Der dokumentenbasierte (fachliche) Ansatz der Datenmodellierung in No- SQL-Datenbanken erlaubt eine wesentlich leichtere Anwendungsentwicklung als bei der Verwendung von relationalen Modellen. NoSQL-Datenbanken erfordern jedoch hinsichtlich Architektur und Design der Anwendungen und Verfahren ein Umdenken, da die Verteilung der Dokumente in großen Clustern und das Design der NoSQL-Datenbanken kein transaktionsbasiertes Arbeiten unterstützen. Transaktionen werden jedoch mit fortlaufendem architektonischem Wandel in Richtung lose gekoppelter Microservices anders behandelt und werden bei der Entwicklung nicht innerhalb klassischer relationaler Datenbanken, sondern häufig schon innerhalb der Anwendungsschicht berücksichtigt.

Abbildung 6: Trennung von Indexierung und Suche
Fazit
Die Suchtechnologie Elasticsearch kann immer dann eingesetzt werden, wenn es auf schnelle Suchantworten ankommt und eine einfache Skalierung der Systeme in Bezug auf Leistung oder Speicher gewünscht ist. Mithilfe von Replikation und Sharding können auch sehr große Such-Cluster aufgebaut werden. Die integrierten Replikationskonzepte erhöhen gleichzeitig die Suchgeschwindigkeit und setzen eine effiziente Datensicherung um.
1 https://de.wikipedia.org/wiki/Elasticsearch (abgerufen am 04.04.2022).
2 https://de.wikipedia.org/wiki/Oracle_(Datenbanksystem) (abgerufen am 04.04.2022).
3 https://de.wikipedia.org/wiki/Apache_Lucene (abgerufen am 04.04.2022).
4 https://lucene.apache.org/ (abgerufen am 04.04.2022).
5 https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html (abgerufen am 04.04.2022).
6 Ebd.
7 https://www.elastic.co/de/licensing/elastic-license (abgerufen am 04.04.2022).

