




























Evidenzbasierte Entscheidungsfindung ist von zentraler Bedeutung für die Entwicklung wirksamer politischer Maßnahmen – insbesondere in einer zunehmend digitalisierten Welt. Die Digitalisierung verändert nicht nur die Prozesse und Werkzeuge, die bei der Entscheidungsfindung zum Einsatz kommen, sondern bringt auch neue Herausforderungen mit sich, die eine rasche, zuverlässige und qualitativ hochwertige Entscheidungsfindung erfordern.
Um diesen Herausforderungen erfolgreich zu begegnen, bedarf es klarer Grundlagen, die politische und administrative Entscheidungsträger mit geeigneten Methoden, einer offenen Kultur sowie modernen Technologien unterstützen. Insbesondere auf technologischer Ebene ist der Zugriff auf qualitative Wissens- und Datenfundamente unverzichtbar.
Verfügbarkeit und Qualität öffentlicher Datenbestände sind eine der zentralen Herausforderungen der digitalen Transformation im öffentlichen Sektor. Von einem oftmals schwerfälligen Datenföderalismus bis hin zu überregulierten Rahmenbedingungen, die effektives Datensharing behindern, steht die Verwaltung vor erheblichen Hindernissen. Mit der zunehmenden Integration von KI und Data-Science-Ansätzen in Verwaltungsprozesse treten diese Herausforderungen immer deutlicher zutage, insbesondere in Form von „Datenlücken“, die nur schwer geschlossen werden können.
In der Industrie hat sich der Einsatz synthetischer Daten bei agilen, hochqualifizierten Data-Science-Teams bereits als effektive Methode etabliert, um Datenlücken zu überbrücken und die Datenqualität zu steigern. Dieser Ansatz ermöglicht es, fehlende oder unzureichende Datensätze künstlich zu erzeugen und einzusetzen. Welche Möglichkeiten ergeben sich, wenn dieses technologische Potenzial strategisch auf die Verwaltung übertragen wird? Was wäre, wenn synthetische Daten gezielt und flächendeckend eingesetzt würden, um die öffentliche Verwaltung „datenfähig“ zu machen, Innovationsbarrieren zu überwinden und eine evidenzbasierte Entscheidungsfindung zu fördern?
Dieser Artikel widmet sich genau dieser Fragestellung: der strategischen Erschließung von Datenlücken durch den Einsatz synthetischer Daten in der öffentlichen Verwaltung. Dabei wird beleuchtet, wie dieser technologische Ansatz nicht nur kurzfristige Engpässe lösen, sondern auch langfristig die Grundlage für eine resiliente und datengetriebene Verwaltung schaffen kann.
Evidenzbasierte Entscheidungsfindung als Sicherheitsnetz in digitalen Entscheidungsprozessen
Evidenzbasierte Entscheidungen basieren auf fundiertem Expertenwissen, ergänzt durch qualitative und quantitative Analysen, um verlässliche Handlungsempfehlungen zu ermöglichen. Entscheidend ist der Zugang zu den richtigen Experten, die durch spezifische Wissensmodelle und Erfahrung Kontext und Relevanz schaffen können. Angesichts zunehmender Komplexität, steigender Entscheidungsanforderungen und des demografischen Wandels wird der schnelle und qualitativ hochwertige Abruf von Expertenwissen immer herausfordernder.
Wissensnetzwerke in der Verwaltung sind grundlegend. Um Expertenwissen effektiv bereitzustellen, sind verlässliche und zugängliche Datenquellen essenziell. Digitale Lösungen wie automatisierte Datenanalysen und intelligente Assistenzsysteme sind durch den Fortschritt generativer KI längst Realität, erfordern jedoch ein robustes und vollständiges Datenökosystem als Grundlage. Die Qualität und Verfügbarkeit relevanter Datensätze bleibt eine zentrale Herausforderung, da ohne qualitativ hochwertige Daten fundierte Entscheidungsgrundlagen für Politik und Verwaltung fehlen.
Um das volle Potenzial analytischer Systeme auszuschöpfen, müssen sie stärker an die Lebensrealität von Verwaltung und Bürgern angepasst werden. Entscheidungsträger sind gefordert, regulatorische und organisatorische Hindernisse abzubauen, Datenlücken durch innovative Ansätze zu schließen und die Datenqualität kontinuierlich zu optimieren. So wird eine belastbare Grundlage für datengetriebene, evidenzbasierte Entscheidungen geschaffen.

Abbildung 1: Synthetische Daten schließen die Lücken, die reale Datensätze haben (Quelle: AutomotivIT)
Was sind synthetische Daten
Synthetische Daten sind künstlich generierte Datensätze, die durch datengenerierende Algorithmen oder generative KI erstellt werden. Ursprünglich für spezifische Anwendungsfälle wie Softwaretests oder die Anonymisierung personenbezogener Daten entwickelt, haben sie heute ein breiteres Einsatzspektrum. Sie können bestehende Datensätze ergänzen, deren Informationsdichte erhöhen und datengetriebene Anwendungen optimieren.
Die Erstellung synthetischer Daten erfordert die Definition fachlicher Datenmodelle, die Inhalte, Strukturen, Merkmale und Zusammenhänge festlegen. Diese Modelle bilden den Rahmen für die Datengenerierung und müssen auf die Zielstellungen, Bedarfe und Anforderungen abgestimmt sein. Die Generierung synthetischer Daten setzt daher eine klare fachliche Klärung und präzise Zieldefinition voraus.
Synthetische Daten werden in der Praxis von KI-Entwicklern und Data Scientists erzeugt, um die Qualität von Trainingsdaten zu verbessern. Ein Beispiel findet sich im Automotive-Bereich bei der Entwicklung von Bilderkennung im autonomen Fahren.1
Da Erhebung und Verarbeitung von Videodaten aus Fahrzeugsensoren ressourcenintensiv sind, setzen Entwicklerinnen und Entwickler zunehmend auf künstlich generierte Daten, die mit Game-Engines aus der Computerspielbranche erzeugt werden.2, 3
Ein weiteres Beispiel für synthetische Daten ist das Feintuning großer Sprachmodelle (LLMs) für spezifische Branchenzwecke, wie etwa die Verbesserung von Risikobewertungen im Finanzwesen oder die Optimierung von Lieferketten im Einzelhandel.4
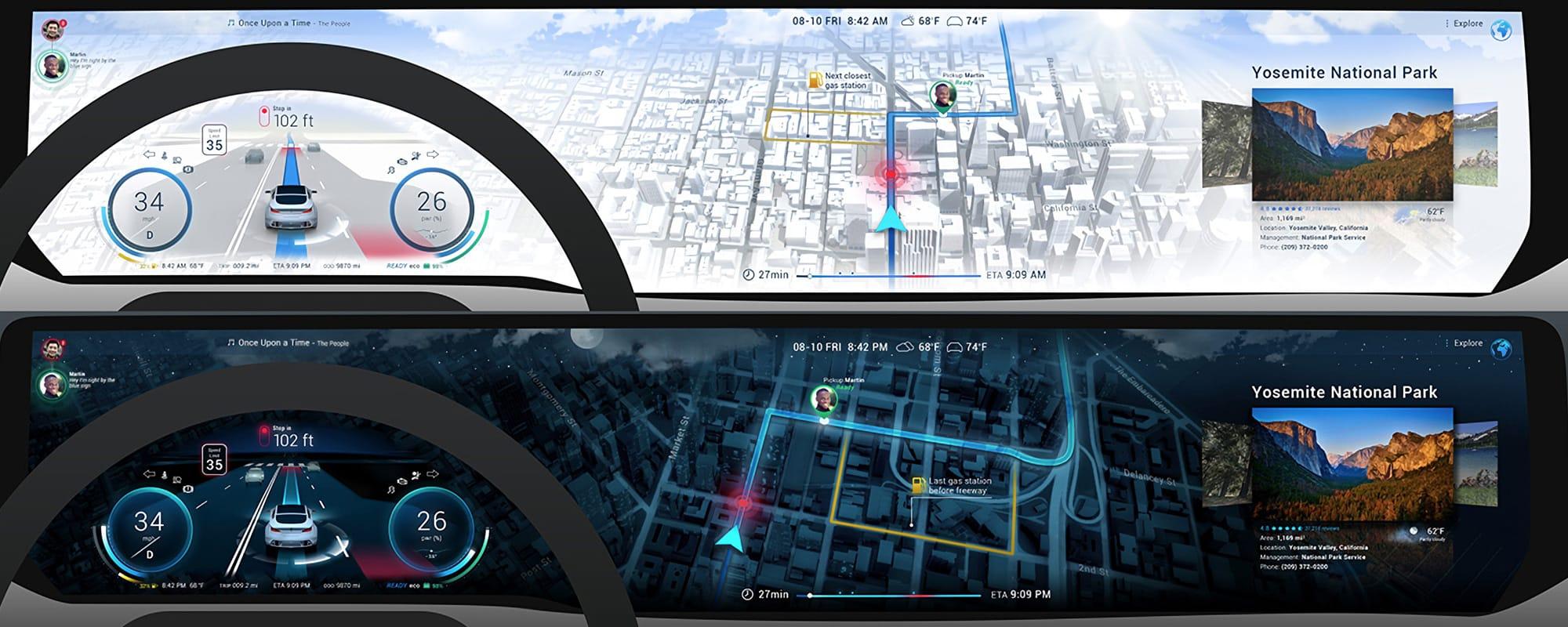
Abbildung 2: Echtzeit-3D-Showcase der Firmen Unity und HERE (Quelle: IoT Automotive News)
Der Weg von synthetischen Daten in die Verwaltung
Synthetische Daten finden schon jetzt ihren Weg in die öffentliche Verwaltung, wie aktuelle Projekte bei Bundesbehörden zeigen. Zum Beispiel nutzt das Forschungsdatenzentrum des BfArM synthetische Daten, um sensible Gesundheitsdaten sicher für Forschungszwecke zugänglich zu machen, ohne den Datenschutz zu gefährden. Ebenso arbeitet das Kompetenzzentrum „Öffentliche IT“ an verschiedenen Ansätzen, synthetische Daten zu nutzen, um Verwaltungsprozesse effizienter und sicherer zu gestalten.5
Das Projekt DaFne entwickelt eine flexible und erweiterbare Plattform zur Generierung synthetischer Daten, die es KI-Forschern ermöglicht, robuste KI-Modelle auch bei unzureichenden Trainingsdaten effizient zu erstellen und in verschiedenen Anwendungsbereichen wie Smart Cities einzusetzen.6
Ein zentraler Anwendungsbereich liegt im Training von KI-Modellen, die auf historischen Daten basieren, um Muster zu erkennen und daraus Vorhersagen für zukünftiges Verhalten abzuleiten. Solche Modelle werden beispielsweise genutzt, um das Nutzerverhalten in Webshops oder das Kaufverhalten von Menschen zu besonderen Zeiten vorherzusagen.
Allerdings funktionieren Vorhersagemodelle – auch bei KI – nur unter den äußeren Bedingungen, die während des ursprünglichen Trainingsprozesses bestanden haben. Veränderungen in den Datenumgebungen oder der Dynamik von Systemen führen oft zu Herausforderungen wie Concept Drift und Data Drift, bei denen die Modellleistung mit der Zeit abnimmt. Um diesen Veränderungen zu begegnen, setzen moderne Ansätze auf kürzere und häufigere Lernzyklen, sodass KI-Modelle kontinuierlich mit aktuellen und relevanten Daten trainiert werden können.7, 8
Es gibt zahlreiche Anwendungsfälle, bei denen das Lernen aus der Vergangenheit nicht erforderlich ist, da klare Zielstellungen für die Zukunft bereits definiert sind. Ein Beispiel dafür ist die Erstellung von Datenmodellen für die Dokumentenklassifizierung: Hier kann Expertenwissen direkt genutzt werden, um gezielt Trainingsdaten zu generieren. Ebenso lassen sich Texte generieren, die barrierefreie Sprache fördern, indem man sich an festgelegten Konzepten und Zielvorgaben orientiert, anstatt vergangene Sprachmuster zu analysieren.
Künftig könnte die Analyse von Hitzeentwicklung in Städten und Kommunen erheblich durch den Einsatz synthetischer Datensätze verbessert werden. Mithilfe der Interpolation realer Sensordaten und der Integration spezieller Klimamodelle können präzise Vorhersagen zur Temperaturentwicklung in verschiedenen Stadtgebieten getroffen werden. Diese Ansätze ermöglichen es, auch in Bereichen mit unzureichender Sensorabdeckung detaillierte und belastbare Aussagen zu treffen, wodurch städtische Klimaanpassungsmaßnahmen gezielter geplant und umgesetzt werden können.9
Diese Ansätze zeigen, dass synthetische Daten nicht nur dazu dienen, Vergangenes zu simulieren, sondern auch innovative und zielgerichtete Lösungen für zukunftsorientierte Anwendungen zu schaffen. Die Einsatzmöglichkeiten sind äußerst vielfältig und noch längst nicht ausgeschöpft. Gerade diese Flexibilität eröffnet neue Perspektiven, wie Technologie eingesetzt werden kann, ohne dabei durch historische Daten limitiert zu sein.
Concept Drift tritt auf, wenn sich die zugrunde liegenden Zusammenhänge oder Muster in den Daten ändern, sodass das Modell auf Basis veralteter Annahmen arbeitet und seine Vorhersagequalität abnimmt.
Data Drift beschreibt Veränderungen in den statistischen Eigenschaften der Eingabedaten wie Verteilungen oder Merkmale, die zu Abweichungen in den Modellergebnissen führen können, auch wenn die zugrunde liegenden Konzepte konstant bleiben.
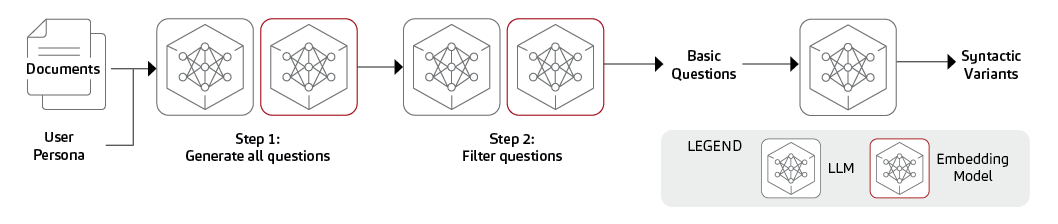
Abbildung 3: Eine Übersicht über eine dreistufige Pipeline zur Generierung synthetischer Daten für die Abrufauswertung (Quelle: NVIDIA (eigene Darstellung))
Risiken verstehen und meistern
Der Einsatz synthetischer Daten erfordert nicht nur klare Standards und strenge Kontrollen, sondern auch eine transparente Nachweis- und Kennzeichnungspraxis, um ihre Nutzung nachvollziehbar und vertrauenswürdig zu gestalten. Eine solche Kennzeichnung sollte sicherstellen, dass Entscheidungen, die teilweise oder vollständig auf synthetischen Daten beruhen, mit Gültigkeits- und Genauigkeitswerten versehen werden. Dies ermöglicht es der Entscheidungsebene, die Grenzen und Unsicherheiten der Datenbasis besser zu verstehen und fundierte Bewertungen vorzunehmen.
Klar definierte Nachweisprozesse für synthetische Daten sollten aufzeigen, welche Teile der Analyse auf realen Daten basieren und welche durch synthetische Ergänzungen erzeugt wurden. Solche Transparenzmechanismen sind essenziell, um die Aussagekraft von Ergebnissen in komplexen Szenarien wie „Was-wäre-wenn“-Simulationen einzuschätzen. Zudem fördert die klare Kennzeichnung datenbasierter Entscheidungen das Vertrauen in intelligente Systeme.
Mit einer gut dokumentierten und standardisierten Kennzeichnungspraxis können synthetische Daten nicht nur dazu beitragen, datenbasierte Diskussionen und Analysen zu beschleunigen, sondern auch eine verlässliche Grundlage für strategische Entscheidungen in der öffentlichen Verwaltung schaffen.
Fazit
Synthetische Daten bieten enormes Potenzial, um datengetriebene Innovationen zu fördern und gleichzeitig die Herausforderungen moderner Datenökosysteme zu bewältigen. Besonders in der öffentlichen Verwaltung, die sich häufig mit fragmentierten Datenbeständen, strengen Datenschutzauflagen und regulatorischen Hürden konfrontiert sieht, werden synthetische Daten eine zentrale Rolle spielen. Sie schließen Datenlücken, erhöhen die Datenqualität und ermöglichen präzise Analysen und Simulationen, die für evidenzbasierte Entscheidungsprozesse unerlässlich sind – ohne aus datenschutzrechtlichen Gründen bedenklich zu sein.
Ein gut organisiertes Datenmanagement ermöglicht es, das Potenzial synthetischer Daten gezielt zu bewerten und effektiv zu nutzen, um der Digitalisierungsstrategie der Organisation einen innovativen und zukunftsorientierten Impuls zu verleihen. Damit werden neue Standards gesetzt, die nicht nur für den öffentlichen Sektor, sondern auch für die Privatwirtschaft richtungsweisend sein können. Die gezielte Integration synthetischer Daten ebnet so den Weg für eine zukunftsorientierte, flexible und datengetriebene Gesellschaft.
Autor

Franz Böhmann ist Senior Business Consultant für künstliche Intelligenz im Bereich Public Sector. Er berät mit langjähriger Erfahrung KI- und Datenprojekte bei Landes- und Bundesbehörden im Bereich des Anforderungs- und Produktmanagements. Franz Böhmann ist Master of Engineering für Informations- und Kommunikationstechnologie und studierter Wirtschaftspsychologie.
Quellen
Quellen
1 Michael Vogel: Warum autonomes Fahren von sythetischen Daten abhängt, automotive IT 2022
2 Marc: Unity Game Engine: Wieso es ohne die Spieleindustrie kein autonomes Fahren gäbe, Mobiliy Rockstars 2021
3 Unity and HERE collaborate on real-time 3D In-Vehicle Experience, IoT Automotive News
4 Tanay Varshney and Chintan Patel: Creating Synthetic Data Using Llama 3.1 405B, Nvidia Developer 2024
5 Katharina Schneider: Forschung meets Datenschutz: Mit Künstlicher Intelligenz sythetische Gesundheitsdaten analysieren, Bundesinstitut für Arzneimittel und Medizinprodukte 2022
6 Hitec: Plattform Data Fusion. Generator für die Künstliche Intelligenz (DaFne), Hamburger Informatik Technologie-Center e. V.
7 Moez All: Understanding Data Drift and Model Drift: Drift Detection in Python, datacamp 2023
8 Amin Shahraki, Mahmoud Abbasi, Amir Taherkordi, Anca Delia Jurcut: A comparative study on online machine learning techniques for network traffic streams analysis, ScienceDirect 2022
9 Werner Achtert: Daten nutzen für eine intelligente Kommune, msg systems ag